2025南软统计模型期末复习
本文为2024统计模型期末试卷回忆版,既作为课程复习笔记,也希望通过系统梳理,加深对算法思想与应用场景的认识。
- 其中,简答题8道+计算题5道
- 2024版简答题新增了部分我认为会考的内容作为复习,所以有12道,实际只有8道
- 2025统计模型计算题新增了
Γ函数作为考点,其他的题目大同小异。 - 回忆版仅供参考。
简答题
- 简述 EM 算法的基本思想、主要步骤,并说明其优缺点与应用场景。
- 何为聚类?简述 K-means 聚类算法的基本流程及其优缺点。
- 什么是层次聚类?写出两种常用的簇间距离计算方法及其变种。
- 简述分类问题中的:二分类、多分类、多标签分类与排序问题的区别及应用场景。
- 简述训练集、验证集、测试集在分类问题中的作用与区别。
- 简述决策树分类算法,并说明 C4.5 相比 ID3 的主要改进。
- 给出泊松分布的概率密度函数,描述参数k和的含义。
- 给出正态分布的概率密度函数,以及均值和方差。
- 写出四种常见概率分布(二项分布、Poisson、指数、正态),并说明各自应用场景。
- 什么是 N-Gram 模型?解释 Unigram、Bigram、Trigram,并说明其在语言建模中的作用。
- 给出NLP的典型任务,以及其特征应用。
- 什么是词项-文档矩阵,如何构造?
计算题
K-means 聚类算法计算
给定如下样本点:
A(1,1),B(2,1),C(5,4),D(6,5)
初始聚类中心为 μ₁(1,1),μ₂(5,4)。请完成 第一次 K-means 迭代:
① 样本分配
② 计算新的聚类中心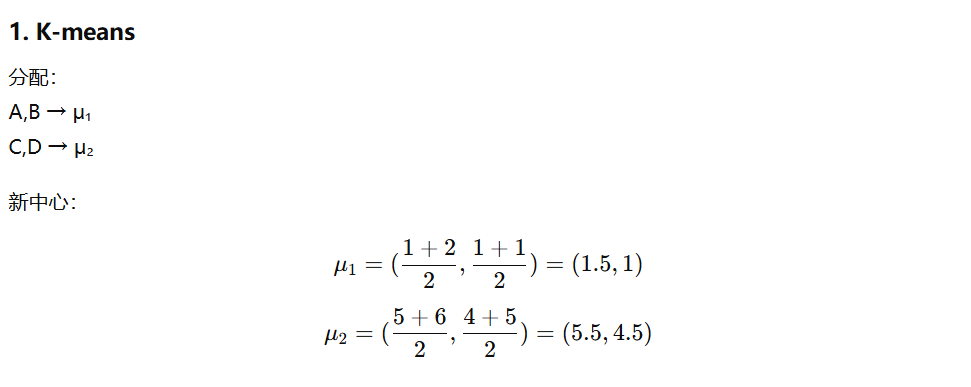
正态分布极大似然估计
给定样本 x1,x2,…,xn来自正态分布 N(μ,σ2)
① 写出似然函数hexo clean
② 写出对数似然函数
③ 对参数求偏导,给出 μ 和 σ2 的极大似然估计值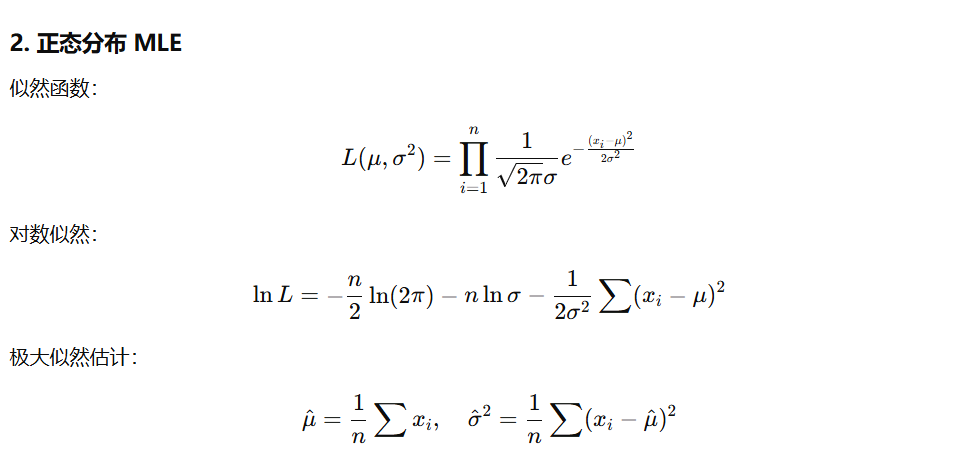
朴素贝叶斯分类计算
已知某分类问题中先验概率和条件概率如下:
P(C1)=0.6, P(C2)=0.4
P(x∣C1)=0.2, P(x∣C2)=0.5使用全概率公式计算后验概率 P(C1∣x) 与 P(C2∣x) ,并给出分类结果。

Bigram 语言模型计算
语料为:
I love machine learning① 写出该句子的 Bigram 表示
② 计算句子概率
词袋模型计算
给定语料库:
文档1:I love NLP
文档2:I love machine learning① 构建词汇表
② 构造对应的词项–文档矩阵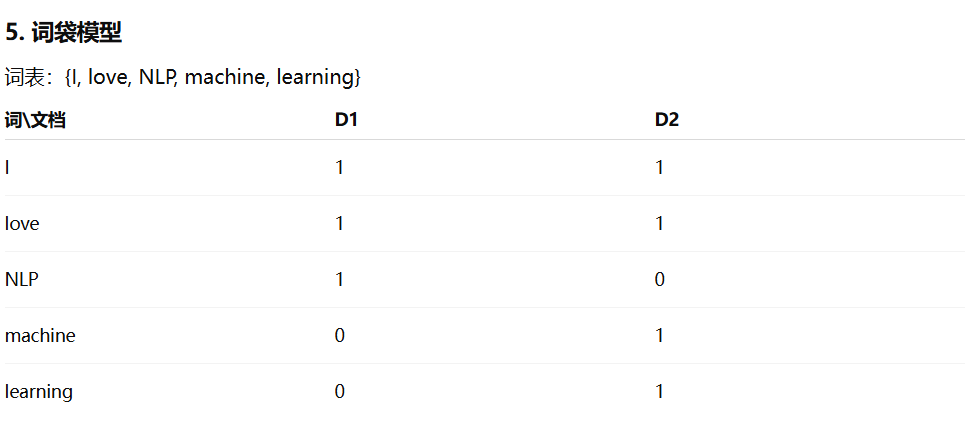
相关推荐

2026-02-06
2025南软软件安全期末复习
本文是对《软件安全》课程期末内容的系统性复习与梳理,围绕软件漏洞、恶意代码、安全开发生命周期(SDL)、安全需求与设计、软件版权与法律等核心知识点,对教材中的重点概念、常见考点和易混淆内容进行了整理与归纳。 2025冷门考点:威胁建模、 Windows安全漏洞保护的基本技术及其存在的问题 第一章 什么是零日(0day)漏洞?什么是零日(0day)攻击?(2024) 未公开披露的软件漏洞,没有给软件厂商时间去打补丁或给出解决方案。 攻击者利用零日漏洞开发攻击工具攻击 为什么说面对当前的全球网络空间安全威...

2026-02-10
2025南软高级软件设计期末复习
高级软件设计简答题汇总 设计模式和类库有什么不同 定义与目的 解决问题,重复使用的框架,经过验证的最佳实践,解决设计问题 封装特定功能的类和接口的集合,提供具体实现 抽象级别 更高级别抽象,方法论,组织代码和模块 具体实现,提供可直接使用的代码 通用性和使用范围 通用性更高,适合多种语言和项目,举例 类库与特定编程语言绑定,Java Spring框架 重用程度 重用思想和方法,而非代码 重用代码 工厂设计模式的三个OO原则 单一职责原则 一个类应当只有一个引起变化的原因。创建对...